
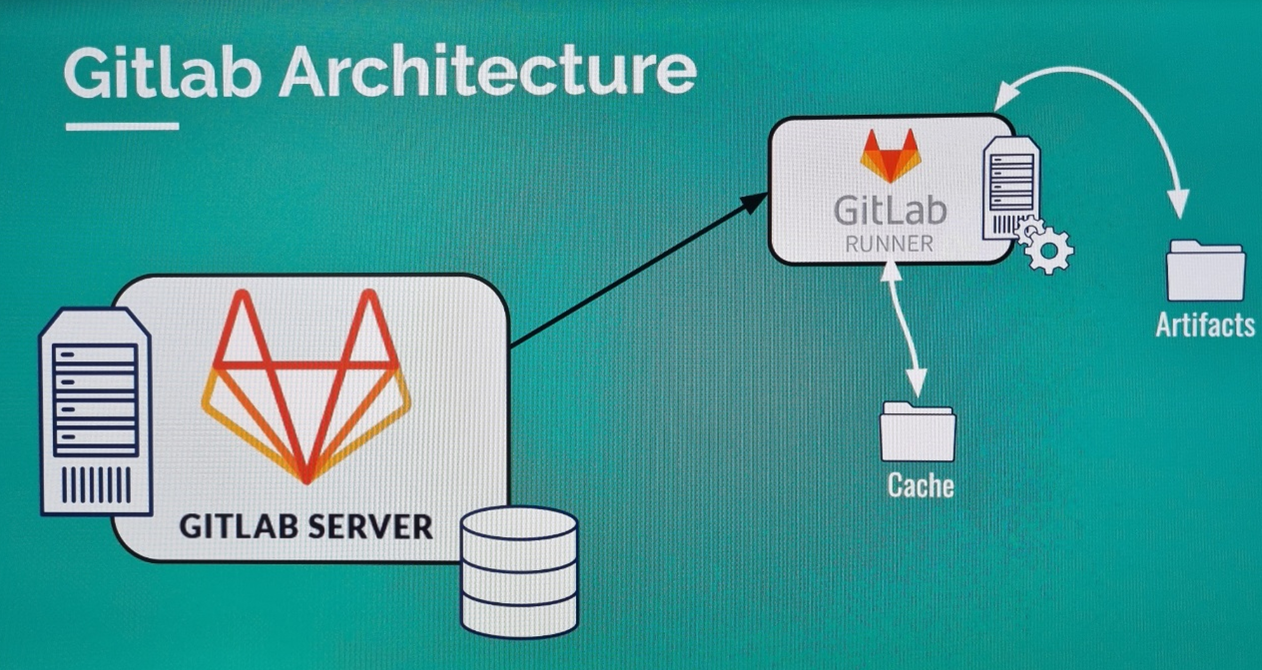
## 깃랩러너 서버에 캐시 저장
- Cache 는 key 와 paths 로 구성
- 전역으로 공통 사용
image: node:10
stages:
- build
- test
- deploy
- deployment tests
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- node_modules/
build website:
stage: build
script:
- echo $CI_COMMIT_SHORT_SHA
- npm install
- npm install -g gatsby-cli
- gatsby build
- sed -i "s/%%VERSION%%/$CI_COMMIT_SHORT_SHA/" ./public/index.html
artifacts:
paths:
- ./public
test artifact:
image: alpine
stage: test
script:
- grep -q "Gatsby" ./public/index.html
test website:
stage: test
script:
- npm install
- npm install -g gatsby-cli
- gatsby serve &
- sleep 3
- curl "http://localhost:9000" | tac | tac | grep -q "Gatsby"
deploy to surge:
stage: deploy
script:
- npm install --global surge
- surge --project ./public --domain instazone.surge.sh
test deployment:
image: alpine
stage: deployment tests
script:
- apk add --no-cache curl
- curl -s "https://instazone.surge.sh" | grep -q "Hi people"
- curl -s "https://instazone.surge.sh" | grep -q "$CI_COMMIT_SHORT_SHA"
===============================================
In this lecture, we're going to take a look at how we can use caches in order to optimize the build
speed.
You have probably noticed that some of the jobs need a lot of time to run, especially the big jobs
it needs to download some dependencies before it can run.
And this takes a lot of time now compared to more traditional S.I servers like JENKINS'.
This extra time it takes to download a docker image, download the dependencies and everything may seem
like forever.
In case you're wondering why digital is behaving in this way, you need to think back to the architecture
of Hitler.
And we'd said previously that every job is starting in a clean environment.
So we download a clean dukkha image and on top of that we have to code from our git repository.
But we have absolutely no other dependencies, no other code that has been generated previously from
the previous jobs.
So we are always starting new.
Like when you're first setting up your project locally on a machine, you have to run NPM install to
get everything installed, all the dependencies.
And this is not only valid for node in this case, it's very different any programming language, but
because it's rarely the case that you are working on a project and you don't have external dependencies.
And as we know, we do not store external dependencies in our data repository.
But rest assured, there is a solution for this, and this can make our jobs a bit faster.
Using gashes is possible to speed up the execution of the job by instructing it to hold onto some files
that we may later need, and if you're wondering where, what should we?
And as we said, we need to download all this external project dependencies.
So an ideal candidate for caching are exactly this external project dependencies that we are not storing
it and that we need to download all the time.
So if we can instruct Getler like, hey, we might need this file soon, so don't throw them away or
don't download them all the time, keep them somewhere.
Then this can make our jobs around faster.
Now, in our case, all these dependencies are located in a folder called Noad Underscore Module's,
and this is exactly the folder that we want to save.
So let's go ahead and change our pipeline a bit.
Now, here we have to build stage, and this is one of the stages that really needs to download all
the dependencies, especially because of this comment npm install.
So for that reason, let's take a look at how we can optimize this and we can instruct now to store
the files.
And we can do that by using cash.
When we're using cash, we first have to specify a key and a path.
I'm going to start with the path because this is probably the easiest to understand.
We have to tell Getler what to save and and we are only interested in saving the node modules because
everything which is inside the node modules is something that will be later downloaded and we do it
again.
So it is definitely a good idea to save the node modules.
The second part regarding the cache is specifying a key.
Now we need somehow to identify when we can use this cache.
Now we can specify here a key as a string, which can be something like my cache.
But it's actually a good practice to have a cash that is based on a specific branch.
Now, currently we only have one branch and that is master and we any way to npm install, we will check
again if there are any outdated dependencies or any dependencies that do not match.
Compared to what we have inside module's, but using this environment variable that is provided by the
lab, we can get the reference to the current price that we are working on.
So this key here, if we are master, will be master.
Or within a specific branch would be something like feature whatever.
It's much easier to use this predefined environment variable from Gitlow.
Now, there's one more thing, and this is valid with a lot of things in Gitlow.
We can specify this on this JOP level.
Or we can globally specified, so if I getting this out of here.
And moving this here outside from any particular job, this will be the global cash conflagration,
and this is actually quite a good thing because not only to build website job needs this cash, but
most likely test website as well because it's doing NPM install.
So for that reason, it might be a good idea to make this cash globally.
This also means that this cash will be used when running other jobs, which actually don't need a cash.
So it's totally up to you how you want to configure it, but definitely it's a bit easier to do it like
this.
Now, let's take a look at how this performs and if it was worth building it in.
Let's take a look at to build websites up and right on top, you will see fatele fail does not exist
and this is right under checking cash for Mossler and this is exactly what Getler is supposed to do.
It's supposed to first check if there's a cash.
And in this case, of course, there isn't no there is no cash because we haven't actually created one.
So the first one of this job, this is definitely fine.
Now, let's crawl towards the bottom of it.
You will now see that.
Gottleib is starting to create a cash creating cash monster, and it has found a bunch of files and
what it actually does.
It takes all those files, it creates a zip archive, and it's uploading that archive somewhere so it
can later download it.
Now, let's take a look at one of the other jobs in our pipeline, and that is the best website.
And what test website will do when starting this job is to check the cash and again identify before
the cash is Mustoe because this is our branch.
So this is why it says overall checking cash for muster.
And this time it finds a cash because we have actually uploaded a cash previously from the bill to job.
And it's not downloading this cash and it doesn't have to download all the dependencies.
And then at the end, it will again save all the files that it has and upload them again.
So in this way, the cash will be all the time updated, and especially the NPM install command that
we have here will make sure that the dependencies that we have are all the time up to date, even produce
a cash.
Now, let's run again the pipeline from the beginning to see if we get any improvements.
I'm going to click here, run pipeline.
I don't arrange for my staff and I don't have any variables that I want to define, so I'll simply click
on Pipeline.
Now, if you take a look at the total execution time for the last one and compared to previous jobs.
We'll see that we have like a 20 seconds improvement, and that may not seem a lot, but we also do
not have a lot of dependencies and we have also not configured this properly because we have enabled
the global cash.
But not all the jobs need that global cash.
So for that reason, this is not 100 percent optimal and it can be better improved.
But as a starting point, is this all that you need to know regarding how caches work or are supposed
to work?
There's one final thing I wanted to show you, and sometimes it happens that cashes, misbehave and
make jobs fail or totally unexpected reason.
And what you can do from catalepsy is to clear the caches and that can be done from here, clear on
caches.
And if you click it, you will be able to empty the caches.
And then when you start the pipeline again, you will have no caches.
So this is like a hidden thing that you should know about.
If you are massively using caches in your projects, it may happen that you have such problems with
caches, then this is how we can clear it.
Now, let's recap for a second, we have defined here a global cash, we have defined a key and using
this environment variable from GitHub, we are specifying the key to the current branch where this code
is being saved.
And we have defined only one path that we need.
But in case there are multiple paths, you can simply add one below node modules or whatever else you
are using and they will be automatically saved by Getler.
So the way it goes is that Gottleib looks for cache entries based on the key specified, and if something
is available, it will be downloaded before the job starts right at the beginning of the execution of
the job and again after the job has finished, the cache will be updated with the latest version in
case something has changed.
'[AWS] > GITLAB' 카테고리의 다른 글
| 런타임(Runtime) 이란? (0) | 2022.02.15 |
|---|---|
| [Node.js] npm이란? (0) | 2022.02.15 |
| 27장. 파이프라인 트리거 / 실패한 작업 재시도 / 파이프라인 일정 (0) | 2022.02.14 |
| 26 (0) | 2022.02.11 |
| 25 (0) | 2022.02.11 |



댓글