www.youtube.com/watch?v=IZVVuOtGMKo

## 우분투 설치

## 도커 설치



- sudo docker run hello-world 실행 & 테스트

## 젠킨스 설치

- OpenJDK 설치



- (옵션) 젠킨스를 도커 이미지로 구동
: docker run -d -p 9090:8080 --name jenkins123 jenkins/jenkins
: docker ps

- locate jenkins 로 로그 위치 확인

- docker stop 85fa && docker rm 85f (임시 젠킨스 도커 삭제)


## Gitlab 설치


- docker pull gitlab/gitlab-ce


- gitlab 도커 이미지 구동
: docker run -d -p 443:443 -p 80:80 -p 22:22 --name gitlab gitlab/gitlab

## 젠킨스 & Flask 소개


- Flask 는 매우 가벼운 웹 개발 프레임 워크이다.
- API 스위치를 만드는데 사용된다.
- API 및 배송이 쉽고 WSGI 커넥터를 제공한다.
: 실제로 어플리케이션을 클라이언트와 연결하는데 도움이 된다.




- 사전작업
: $ python3 -m pip install flask
- flask-try.py 생성

- app = Flask(__name__) -> 코드 아래에 전달할 메인 메소드의 이름
- 그런 다음 어플리케이션을 라우팅 할 것입니다.
- 웹 브라우저를 열때마다 실제로 API를 만들고 있습니다.
- 또는 로컬 호스트에서 특정 메시지를 볼수 있습니다.
- 인덱스를 정의하고, 그 후에 hello flask 를 반환합니다.

from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'Hello Flask'
if __name__ == '__main__':
app.run(port = 8000,debug=True)



## 로드맵

## 감정 분석



## Programming Flask API
- ML Model Deployment


- app.py 파일 생성



- 깃허브 주소 참고
github.com/dhrbduf/Deployement-of-NLP-Model/blob/master/app.py

- Importing the Libraries

- warnings 오타 수정


- Importing the dataset


- Cleaning of Data


- Remove twitter handles (@user)

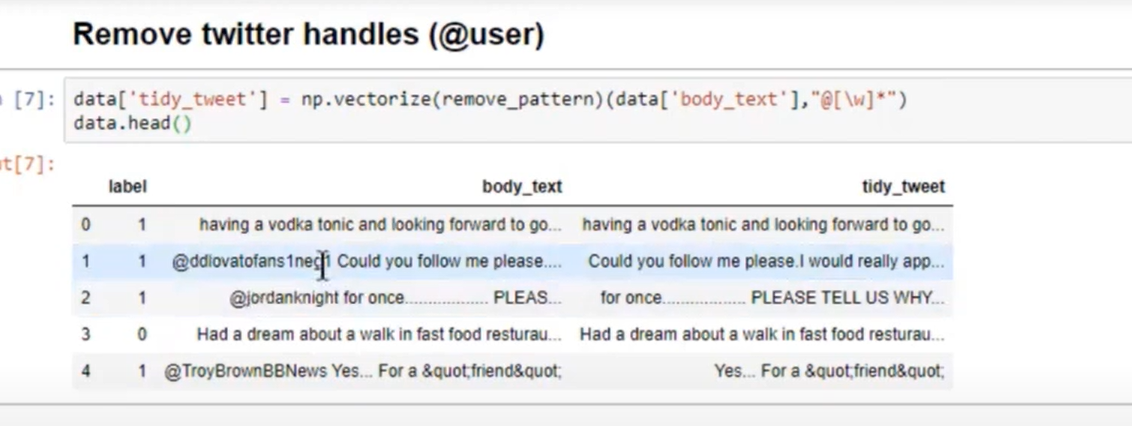

- 원하지 않는 특수문자나 점 제거

- Remove special characters, numbers, punctuations

- Tokenize the tweets (표식화하다, 표식을 붙이다)
- 형태소 분석



- Joining the tokenized word in the same data

- Adding other column for length of the tweet and punctuation



- body_len , punct% 컬럼 생성


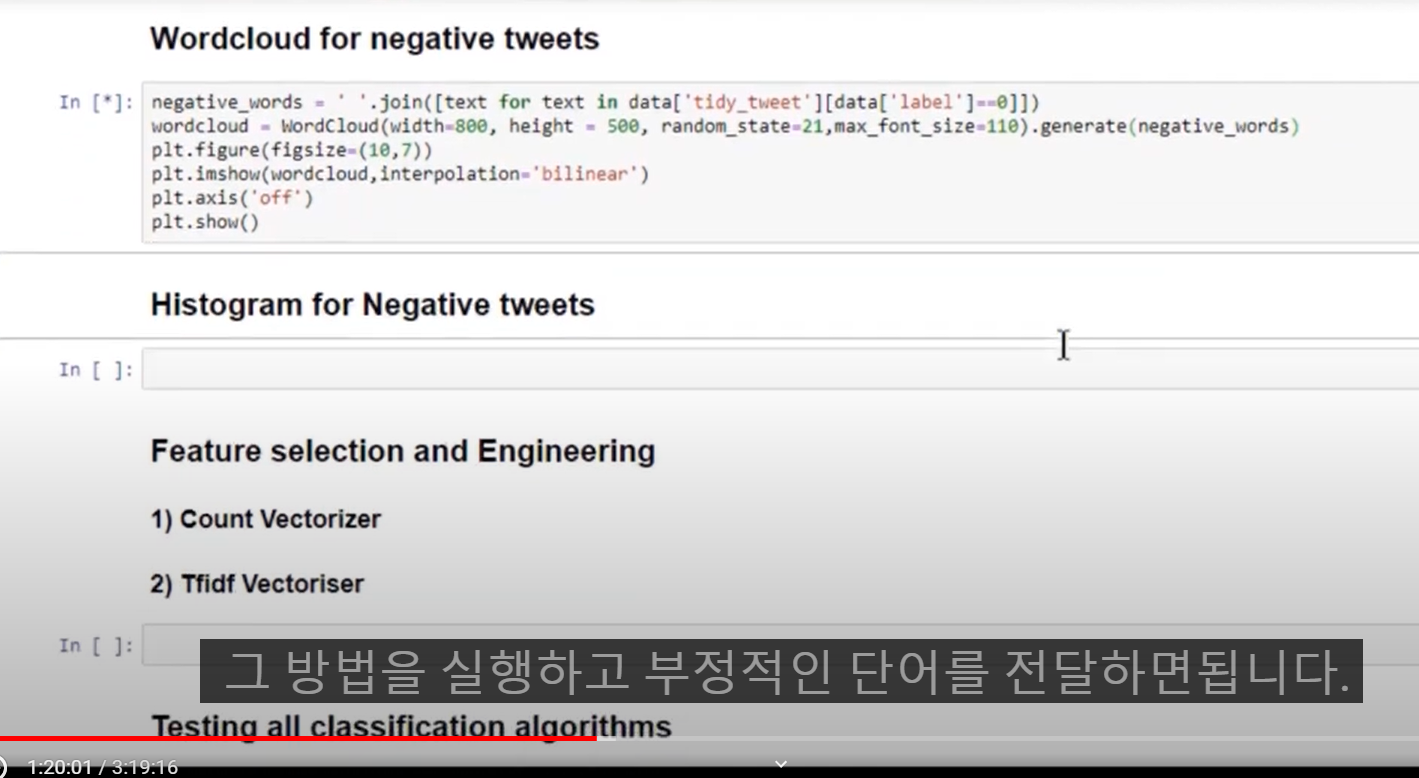
- Generating word cloud for data
: all_words = ' '.join([text for text in data['tidy_tweet']])





- Wordcloud for negative tweets




## Programming Flask API
- ML Model Deployment (Understanding WebPages)



- home.html

- post 메소드 활용
- 예측버튼은 POST 명령을 생성하고 액션을 넣음

- result.html
: 1 이면 부정적
: 0 이면 긍정적

## Programming Flask API (Part 2)

- app.py 소스 분석
github.com/dhrbduf/Deployement-of-NLP-Model/blob/master/app.py

| from flask import Flask,render_template,url_for,request |
| import pandas as pd |
| import numpy as np |
| from nltk.stem.porter import PorterStemmer |
| import re |
| import string |
| from sklearn.feature_extraction.text import CountVectorizer |
| from sklearn.linear_model import LogisticRegression |
| ## Definitions |
| def remove_pattern(input_txt,pattern): |
| r = re.findall(pattern,input_txt) |
| for i in r: |
| input_txt = re.sub(i,'',input_txt) |
| return input_txt |
| def count_punct(text): |
| count = sum([1 for char in text if char in string.punctuation]) |
| return round(count/(len(text) - text.count(" ")),3)*100 |
| app = Flask(__name__) |
| data = pd.read_csv("sentiment.tsv",sep = '\t') |
| data.columns = ["label","body_text"] |
| # Features and Labels |
| data['label'] = data['label'].map({'pos': 0, 'neg': 1}) |
| data['tidy_tweet'] = np.vectorize(remove_pattern)(data['body_text'],"@[\w]*") |
| tokenized_tweet = data['tidy_tweet'].apply(lambda x: x.split()) |
| stemmer = PorterStemmer() |
| tokenized_tweet = tokenized_tweet.apply(lambda x: [stemmer.stem(i) for i in x]) |
| for i in range(len(tokenized_tweet)): |
| tokenized_tweet[i] = ' '.join(tokenized_tweet[i]) |
| data['tidy_tweet'] = tokenized_tweet |
| data['body_len'] = data['body_text'].apply(lambda x:len(x) - x.count(" ")) |
| data['punct%'] = data['body_text'].apply(lambda x:count_punct(x)) |
| X = data['tidy_tweet'] |
| y = data['label'] |
| # Extract Feature With CountVectorizer |
| cv = CountVectorizer() |
| X = cv.fit_transform(X) # Fit the Data |
| X = pd.concat([data['body_len'],data['punct%'],pd.DataFrame(X.toarray())],axis = 1) |
| from sklearn.model_selection import train_test_split |
| #X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) |
| ## Using Classifier |
| clf = LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True, |
| intercept_scaling=1, l1_ratio=None, max_iter=100, |
| multi_class='auto', n_jobs=None, penalty='l2', |
| random_state=None, solver='liblinear', tol=0.0001, verbose=0, |
| warm_start=False) |
| clf.fit(X,y) |
| @app.route('/') |
| def home(): |
| return render_template('home.html') |
| @app.route('/predict',methods=['POST']) |
| def predict(): |
| if request.method == 'POST': |
| message = request.form['message'] |
| data = [message] |
| vect = pd.DataFrame(cv.transform(data).toarray()) |
| body_len = pd.DataFrame([len(data) - data.count(" ")]) |
| punct = pd.DataFrame([count_punct(data)]) |
| total_data = pd.concat([body_len,punct,vect],axis = 1) |
| my_prediction = clf.predict(total_data) |
| return render_template('result.html',prediction = my_prediction) |
| if __name__ == '__main__': |
| app.run(host='0.0.0.0',port=4000) |
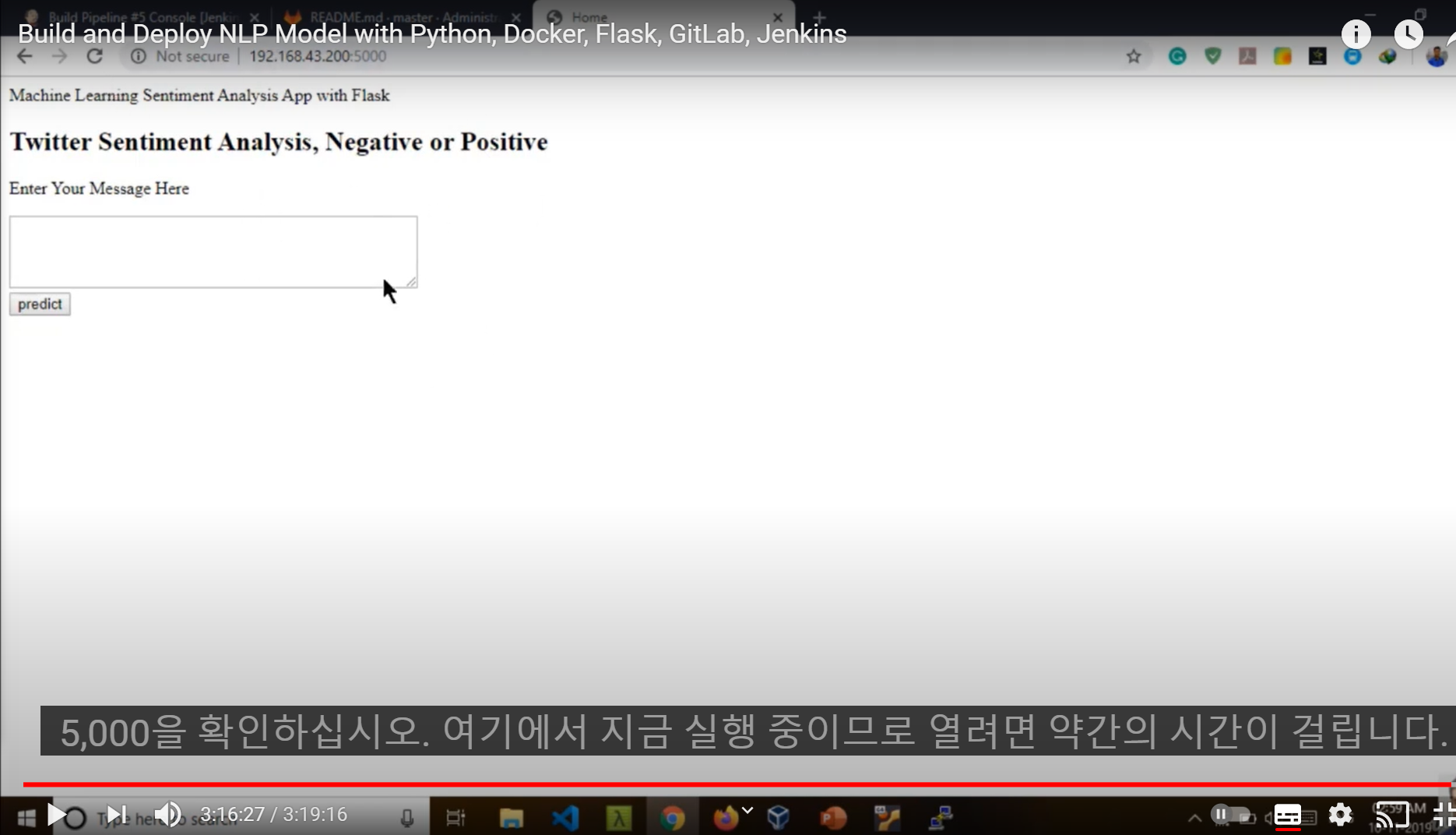
## Programming Flask API (Part 3)

- 코드 준비 -> 모델 구현

- static 파일 설명
- template 파일 설명


- http://127.0.0.1:4000



- 이런 식으로 플라스크 API를 만들 수 있음


## Docker in Nutshell
- ML Deployment Model (Part #1)

- 도커 허브로 이동

- 알파인 이미지 사용


- Dockerfile 생성

- FROM 사용자/이미지명:태그 (첫번째로 우선 도커 이미지 파일이 필요함)
- pip 설치 및 복사
: RUN pip install --upgrade pip

## Docker in Nutshell
- ML Deployment Model (Part #2)

- 현재까지 FLASK API를 작성했고,
- 젠킨스 및 도커 구성을 했고,
- 주된 목표는 우리 자신의 LP 모델을 배포하는 것.
- 도커 스크립트, 도커 이미지를 작성하기로 결정.
- 도커 이미지를 빌드하면 마침내 컨테이너를 얻게 됩니다.
- 최종 사용자가 실행 할 수 있는 어플리케이션을 제공할 수 있다.
- 도커 허브 사이트에서 Alpine 검색
- Alpine 은 5MB 의 기본 이미지이다.

- hub.docker.com/r/frolvlad/alpine-python-machinelearning/tags?page=1&ordering=last_updated

## Dockerfile 작성
- FROM frolvlad/alpine-python-machinelearning:latest (FROM 도커 이미지 사용)
- RUN pip install --upgrade pip (도커 이미지에 RUN으로 pip 업그레이드)
- WORKDIR /app (이 컨테이너 내부에 어플리케이션 폴더 만듬)
- COPY . /app (우리의 모든 것이 해당 응용 프로그램 폴더에 복사 )
- RUN pip install -r requirements.txt
- RUN python -m nltk.downloader punkt
- EXPOSE 4000 (컨테이터 진입 사용 포트)
- ENTRYPOINT ["python"] (컨테이너가 시작할때 항상 실행되는 명령어)
- CMD ["app.py"] (ENTRYPOINT 에서 실행할 어플리케이션)

## Docker in Nutshell
- ML Deployment Model (Part #3)

- 도커 파일을 가상 환경에 복사해야 함.

- github로 파일 복사
- github.com/mdrijwan123/Deployement-of-NLP-Model


- 가상머신 구동
- git 저장소 복제
- 모든 파일을 사용할 수 있다.
- git clone https://github.com/mdrijwan123/Deployement-of-NLP-Model.git

- 빌드 수행
- docker build -t nlp-python:v1 .


- docker images
- nlp-python:v1 이미지 확인

- 도커 구동
- docker run -p 5000:4000 -d --name mynlp nlp-python:v1

- http://IP:5000 접속 (성공)

- 도커 내부로 들어가기
- root@juniper-devstack:/home/nlp/Deployement-of-NLP-Model# docker exec -it mynlp /bin/sh
- 도커 로그 확인하기
- docker logs mynlp

## CI/CD 구성
- ML Model Deployment (Part #1)

- 우리는 API를 만들기 위해 Flask에 파이썬 스크립트를 작성하는 방법을 이해했다.
- 젠킨스는 이 비디오에서 수행 할 모든 종단 간 통합입니다.

- 젠킨스 구동


- 젠킨스 관리 -> GitLab & Generic Webhook Trigger 플러그인 설치


- 깃랩 구동

- 개발자 또는 게스트 사용자는 일부 변경사항만 푸시할 수 있습니다.


- 신규 프로젝트 생성
- my-nlp-model


- 깃랩 리모트 설정 (root 계정 사용하지 말것)
- root@juniper-devstack:/home/nlp/Deployement-of-NLP-Model# git remote -v (기존 리모트 확인)
- root@juniper-devstack:/home/nlp/Deployement-of-NLP-Model# git remote rm origin (기존 리모트 삭제)
- # git remote add origin http://52.79.43.65:1114/root/my-nlp-model.git (신규 리모트 설정)
- # git remote -v (리모트 확인)

- 깃랩에 소스코드 업로드 (commit 수행)
- # git config --global user.email "you@example.com"
- # git config --global user.name "Your Name"
- # git add .
- # git commit -m "commit" (root / gitlabXXX)

- 깃랩 업로드 성공

- Jenkinsfile 설정
- 젠킨스 파이프 라인을 실행하기 위한 이미지에는 몇가지 명령 집합이 있습니다.

- Freestyle project 생성
- simple build 생성

- 소스 코드 관리

- 테스트로 whoami 출력

- 테스트 빌드 수행 성공 (whoami -> jenkins 출력)

- 작업공간을 보면 모든 파일을 사용할 수 있음을 알수 있다.

- 지금까지 깃랩과 연동을 테스트 하였음.

## ML Model Deployment
- Jenkins Pipeline Part #2

- 이제 우리가 원하는 작업을 수행하는 방법을 Jenkins 파이프 라인으로 만들고 싶다.
- 젠킨스 파일을 만들면 괜찮습니다.


- jenkinsfile 생성 후, commit 수행
: vi Jenkinsfile
: git status
: git add .
: git commit -m "commit"
: git push origin master (root / gitlabXXX)

- Jenkinsfile 편집

- Stage 1
- 리포지토리를 복제
- checkout scm

- Stage 2
- Buid Image
- sh 'sudo docker build -t mynlpmodel:v1 .'

- Stage 3
- Run Image
- sh 'sudo docker run -d --name nlpmodel mynlpmodel:v1'

- Stage 4
- Testing
- echo 'Testing..'

## 젠킨스 파이프라인 구성
- Build Pipeline 생성

- Pipeline 수정
: Pipeline script from SCM
: Git
: Repository URL
_ http://52.79.43.XXX:1114/root/my-nlp-model
: Script Path
_ Jenkinsfile


- Build NOW 클릭



- sudo docker ps 로 컨테이너 확인

## 젠킨스 빌드시 에러 발생하면 젠킨스 권한 등록 필요 (sudo visudo)
- sudo: no tty present and no askpass program specified
- jenkins ALL=(ALL) NOPASSWD: ALL


## 젠킨스 이미지 조회
- sudo docker images

## 도커그룹에 젠킨스 유저 등록 (젠킨스에서 도커 사용시 에러 방지)
- sudo usermod -aG docker jenkins
- vi /etc/group 에서 확인


- 도커에 지속적 통합하는 방법

## ML Model Deployment
- Jenkins Pipeline Part #3

- 젠킨스에서 Build Triggers 수정


- 깃랩에서 수정
: URL 복사
: SSL 해제


- 깃랩에서 웹훅 방화벽 오픈 설정

- 깃랩에서 웹훅 테스트
: Test -> Push events

- 후크가 성공적으로 실행되었지만 HTTP 403을 반환한다.

- 젠킨스 -> 환경설정 -> Gitlab -> 인증사용 해제 할것

- 깃랩에서 이벤트 후크가 성공적으로 실행

- 기존 nlpmodel 컨테이너가 존재하여 충돌 에러 발생

- 기존 도커 컨테이너 삭제 필요
- docker stop nlpmodel (컨테이너 정지)
- docker rm nlpmodel (컨테이너 삭제)
- 깃랩에서 소스코드 변경 후, 커밋하면 자동으로 빌드 수행함 (성공)

- docker ps 로 확인

- 웹 접속 및 소스코드 업데이트 성공
'젠킨스' 카테고리의 다른 글
| Jenkins 빌드 스케쥴 설정하기 (0) | 2021.02.08 |
|---|---|
| 젠킨스 스케쥴을 이용하여 업무시간을 단축 하기 (0) | 2021.02.08 |
| 젠킨스 설치 (0) | 2020.12.24 |
| Jenkins Jira 통합 (0) | 2020.12.01 |
| Jenkins를 활용한 CI/CD 4강 - 젠킨스 CI/CD 파이프라인 구성 실습(2) (0) | 2020.11.19 |


댓글